Le protocole HTTP (HyperText Transfer Protocol)
est le protocole le plus utilisé sur Internet depuis 1990. La version
0.9 était uniquement destinée à transférer des données
sur Internet (en particulier des pages Web écrites en HTML. La version 1.0 du protocole (la plus utilisée) permet désormais
de transférer des messages avec des en-têtes décrivant le contenu
du message en utilisant un codage de type MIME.
Le but du protocole HTTP est de permettre un transfert de fichiers (essentiellement au format
HTML) localisé grâce à une chaîne de caractères appelée
URL entre un navigateur (le client) et un serveur Web (appelé d'ailleurs httpd sur les machines
UNIX)
La communication entre le navigateur et le serveur se fait en deux temps:
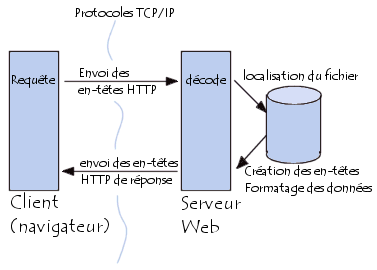
- Le navigateur effectue une requête HTTP
- Le serveur traite la requête puis envoie une réponse HTTP
En réalité la communication s'effectue en plus de temps si on considère le
traitement de la requête par le serveur.
Etant donné que l'on s'intéresse uniquement au protocole HTTP, le traitement du côté serveur ne sera pas
explicité dans le cadre de cet article...
Si ce sujet vous intéresse, référez-vous à l'article sur
le traitement des CGI.
Une requête HTTP est un ensemble de lignes envoyé au serveur par le navigateur.
Elle comprend:
- une ligne de requête: c'est une ligne précisant le type de document demandé,
la méthode qui doit être appliquée, et la version du protocole utilisée. La ligne comprend
trois éléments devant être séparé par un espace:
- La méthode
- L'URL
- La version du protocole utilisé par le client (généralement HTTP/1.0)
- Les champs d'en-tête de la requête: il s'agit d'un ensemble de lignes
facultatives permettant de donner des informations supplémentaires sur la requête
et/ou le client (Navigateur,système d'exploitation,...). Chacune de ces lignes est
composée d'un nom qualifiant le type d'en-tête, suivi de deux points (:) et de
la valeur de l'en-tête
- Le corps de la requête: C'est un ensemble de ligne optionnel devant être
séparé des lignes précédentes par une ligne vide et permettant
par exemple un envoi de données par une commande POST lors de l'envoi de données
au serveur par un formulaire
Une requête HTTP a donc la syntaxe suivante (<crlf> signifie retour chariot ou saut de ligne):
METHODE URL VERSION<crlf>
EN-TETE : Valeur<crlf>
.
.
.
EN-TETE : Valeur<crlf>
Ligne vide<crlf>
CORPS DE LA REQUETE
Voici donc un exemple de requête HTTP:
GET http://www.commentcamarche.net HTTP/1.0
Accept : text/html
If-Modified-Since : Saturday, 15-January-2000 14:37:11 GMT
User-Agent : Mozilla/4.0 (compatible; MSIE 5.0; Windows 95)
| Commande |
Description |
| GET |
Requête de la ressource située à l'URL spécifié |
| HEAD |
Requête de la ressource située à l'URL spécifié |
| POST |
Envoi de données au programme située à l'URL spécifié |
| PUT |
Envoi de données à l'URL spécifié |
| DELETE |
Suppression de la ressource située à l'URL spécifié |
| Nom de l'en-tête |
Description |
| Accept |
Type de contenu accepté par le browser (par exemple text/html). Voir types MIME |
| Accept-Charset |
Jeu de caractères attendu par le browser |
| Accept-Encoding |
Codage de données accepté par le browser |
| Accept-Language |
Langage attendu par le browser (anglais par défaut) |
| Authorization |
Identification du browser auprès du serveur |
| Content-Encoding |
Type de codage du corps de la requête |
| Content-Language |
Type de langage du corps de la requête |
| Content-Length |
Longueur du corps de la requête |
| Content-Type |
Type de contenu du corps de la requête (par exemple text/html). Voir types MIME |
| Date |
Date de début de transfert des données |
| Forwarded |
Utilisé par les machines intermédiaires entre le browser et le serveur |
| From |
Permet de spécifier l'adresse e-mail du client |
| From |
Permet de spécifier que le document doit être envoyé si il a été modifié depuis une certaine date |
| Link |
relation entre deux URL |
| Orig-URL |
URL d'origine de la requête |
| Referer |
URL du lien à partir duquel la requête a été effectuée |
| User-Agent |
Chaîne donnant des informations sur le client, comme le nom et la version du navigateur, du système d'exploitation |
Une réponse HTTP est un ensemble de lignes envoyé au navigateur par le serveur.
Elle comprend:
- une ligne de statut: c'est une ligne précisant la version du protocole utilisé et
l'état du traitement de la requête à l'aide d'un code et d'un texte explicatif. La ligne comprend
trois éléments devant être séparé par un espace:
- La version du protocole utilisé
- Le code de statut
- La signification du code
- Les champs d'en-tête de la réponse: il s'agit d'un ensemble de lignes
facultatives permettant de donner des informations supplémentaires sur la réponse
et/ou le serveur. Chacune de ces lignes est
composé d'un nom qualifiant le type d'en-tête, suivi de deux points (:) et de
la valeur de l'en-tête
- Le corps de la réponse: Il contient le document demandé
Une réponse HTTP a donc la syntaxe suivante (<crlf> signifie retour chariot ou saut de ligne):
VERSION-HTTP CODE EXPLICATION<crlf>
EN-TETE : Valeur<crlf>
.
.
.
EN-TETE : Valeur<crlf>
Ligne vide<crlf>
CORPS DE LA REPONSE
Voici donc un exemple de réponse HTTP:
HTTP/1.0 200 OK
Date : Sat, 15 Jan 2000 14:37:12 GMT
Server : Microsoft-IIS/2.0
Content-Type : text/HTML
Content-Lentgh : 1245
Last-Modified : Fri, 14 Jan 2000 08:25:13 GMT
| Nom de l'en-tête |
Description |
| Content-Encoding |
Type de codage du corps de la réponse |
| Content-Language |
Type de langage du corps de la réponse |
| Content-Length |
Longueur du corps de la réponse |
| Content-Type |
Type de contenu du corps de la réponse (par exemple text/html). Voir types MIME |
| Date |
Date de début de transfert des données |
| Expires |
Date limite de consommation des données |
| Forwarded |
Utilisé par les machines intermédiaires entre le browser et le serveur |
| Location |
Redirection vers une nouvelle URL associée au document |
| Server |
Caractéristiques du serveur ayant envoyé la réponse |
Ce sont les codes que vous voyez lorsque le navigateur n'arrive pas à vous
fournir la page demandée. Le code de réponse est constitué de trois chiffres:
le premier indique la classe de statut et les suivants la nature exacte de l'erreur.
| Code |
Message |
Description |
| 10x |
Message d'information |
Ces codes ne sont pas utilisés dans la version 1.0 du protocole |
| 20x
| Réussite |
Ces codes indiquent le bon déroulement de la transaction |
| 200 |
OK |
La requête a été accomplie correctement |
| 201 |
CREATED |
Elle suit une command POST, elle indique la réussite,
le corps du reste du document est sensé indiquer l'URL
a laquelle le document nouvellement créé devrait se trouver. |
| 202 |
ACCEPTED |
La requête a été acceptée, mais la procédure qui suit
n'a pas été accomplie |
| 203 |
PARTIAL INFORMATION |
Lorsque ce code est reçu en réponse à une commande GET, cela
indique que la réponse n'est pas complète. |
| 204 |
NO RESPONSE |
Le serveur a reçu la requête mais il n'y a pas d'information a renvoyer |
| 205 |
RESET CONTENT |
Le serveur indique au navigateur de supprimer le contenu des champs d'un formulaire |
| 205 |
PARTIAL CONTENT |
Il s'agit d'une réponse à une requête comportant l'en-tête range.
Le serveur doit indiquer l'en-tête content-Range |
| 30x |
Redirection |
Ces codes indiquent que la ressource n'est plus à l'emplacement indiqué |
| 301 |
MOVED |
Les données demandées ont été transférées a une
nouvelle adresse
|
| 302 |
FOUND |
Les données demandées sont à une nouvelle URL, mais ont cependant
peut-être été déplacées depuis...
|
| 303 |
METHOD |
Cela implique que le client doit essayer une nouvelle adresse, en essayant de préférence
une autre méthode que GET
|
| 304 |
NOT MODIFIED |
Si le client a effectué une commande GET conditionnelle (en demandant
si le document a été modifié depuis la dernière fois) et que le document
n'a pas été modifié il renvoie ce code.
|
| 40x |
Erreur dûe au client |
Ces codes indiquent que la requête est incorrecte |
| 400 |
BAD REQUEST |
La syntaxe de la requête est mal formulée ou est impossible à satisfaire |
| 401 |
UNAUTHORIZED |
Le paramètre du message donne les spécifications des formes d'autorisation acceptables.
Le client doit reformuler sa requête avec les bonnes données d'autorisation |
| 402 |
PAYMENT REQUIRED |
Le client doit reformuler sa demande avec les bonnes données de paiement |
| 403 |
FORBIDDEN |
L'accès à la ressource est tout simplement interdit |
| 404 |
NOT FOUND |
Classique! Le serveur n'a rien trouvé à l'adresse spécifiée. Parti
sans laisser d'adresse ... :) |
| 50x |
Erreur dûe au serveur |
Ces codes indiquent qu'il y a eu une erreur interne du serveur |
| 500 |
INTERNAL ERROR |
Le serveur a rencontré une condition inattendue qui l'a empéché
de donner suite à la demande (Comme quoi il leur en arrive des trucs aux serveurs ...) |
| 501 |
NOT IMPLEMENTED |
Le serveur ne supporte pas le service demandé (on ne peut pas tout savoir faire ...) |
| 502 |
BAD GATEWAY |
Le serveur a reçu une réponse invalide de la part du serveur auquel il essayait
d'accéder en agissant comme une passerelle ou un proxy |
| 503 |
SERVICE UNAVAILABLE |
Le serveur ne peut pas vous répondre à l'instant présent,
car le trafic est trop dense (Toutes les lignes de votre correspondant sont occupées
veuillez rappeler ultérieurement) |
| 504 |
GATEWAY TIMEOUT |
La réponse du serveur a été trop longue vis à vis du temps
pendant lequel la passerelle était préparée à l'attendre.
(Le temps qui vous était imparti est maintenant écoulé ...)
|
Pour plus d'informations sur le protocole HTTP, le mieux est de se reporter à la RFC 1945
expliquant de manière détaillée le protocole :


| 


