Une URL (Uniform Resource Locator) est une adresse permettant
de localiser un fichier sur Internet de manière unique. C'est grâce à cette adresse
(du genre http://www.commentcamarche.net) qu'il est possible d'effectuer des requêtes
vers des pages web. Lorsqu'une telle requête est effectuée sur Internet, celle-ci circule
grâce à la suite de protocole TCP/IP et en particulier
le protocole HTTP (HyperText Transfer Protocol), permettant
d'envoyer des données encapsulées dans un datagramme contenant un grand nombre
d'en-tête permettant d'identifier par exemple:
- le fichier demandé,
- l'adresse IP du demandeur,
- le navigateur effectuant la requête,
- ...
Pour apprendre à utiliser les CGI, il est essentiel de comprendre comment se
déroule la communication entre le navigateur et le serveur lors de la demande
d'une page web. Pour cela, il est préférable d'avoir des notions sur
le protocole HTTP...
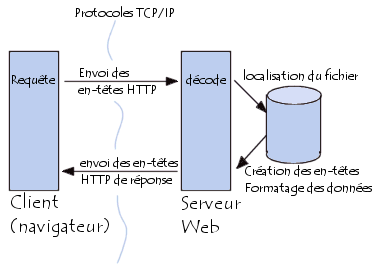
Lorsqu'un navigateur effectue une requête (typiquement par saisie ou clic d'un URL,
ou bien par envoi d'un formulaire), les étapes suivantes se déroulent:
- les données de requête sont envoyées
au serveur sous forme d'en-têtes de requête HTTP
- Lorsque le serveur reçoit la requête, il analyse les en-têtes HTTP,
notamment celui permettant de localiser le fichier demandé.
- Si le serveur trouve le fichier HTML demandé,
il va envoyer au client
(le navigateur) un en-tête de réponse valide (Généralement Success)
et les données créées par l'application
- A la réception
du document, le navigateur affiche le résultat à l'écran.
Dans le cas d'un CGI, le schéma est un petit peu plus compliqué:
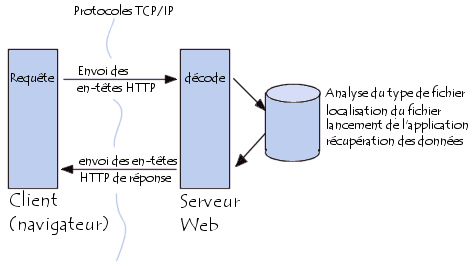
- les données de requête sont envoyées
au serveur sous forme d'en-têtes de requête HTTP
- Lorsque le serveur reçoit
la requête, il analyse les en-têtes HTTP, notamment celui permettant de localiser le
fichier demandé.
- Le serveur va ensuite analyser l'extension du fichier, puis exécuter
l'application associée à ce type de fichier (l'interpréteur Perl dans le cas d'une
extension .pl par exemple), en fournissant à cette application les en-têtes de
requête HTTP sous forme de variable d'environnement.
- L'application va donc s'exécuter
puis fournir des données de sortie (commençant par une formulation d'en-tête
de la forme content-type : text/html) au serveur.
- Le serveur va envoyer au client
(le navigateur) un en-tête de réponse valide (Généralement Success)
ainsi que les données créées par l'application
- A la réception du document, le navigateur affiche le résultat à l'écran.


|



