|
|

LDAP (Lightweight Directory Access Protocol, traduisez Protocole d'accès aux annuaires léger et prononcez "èl-dap") est un protocole standard permettant de gérer des annuaires, c'est-à-dire d'accèder à des bases d'informations sur les utilisateurs d'un réseau par l'intermédiaire de protocoles TCP/IP. Les bases d'informations sont généralement relatives à des utilisateurs, mais elles sont parfois utilisées à d'autres fins comme pour gérer du matériel dans une entreprise. Le protocole LDAP, développé en 1993 par l'université du Michigan, avait pour but de supplanter le protocole DAP (servant à accéder au service d'annuaire X.500 de l'OSI), en l'intégrant à la suite TCP/IP. A partir de 1995, LDAP est devenu un annuaire natif (standalone LDAP), afin de ne plus servir uniquement à accéder à des annuaires de type X500. LDAP est ainsi une version allégée du protocole DAP, d'où son nom de Lightweight Directory Access Protocol.
Le protocole LDAP définit la méthode d'accès aux données sur le serveur au niveau du client, et non la manière de laquelle les informations sont stockées. Le protocole LDAP en est actuellement à la version 3 et a été normalisé par l'IETF (Internet Engineering Task Force). Ainsi, il existe une RFC pour chaque version de LDAP, constituant un document de référence: Ainsi LDAP fournit à l'utilisateur des méthodes lui permettant de:
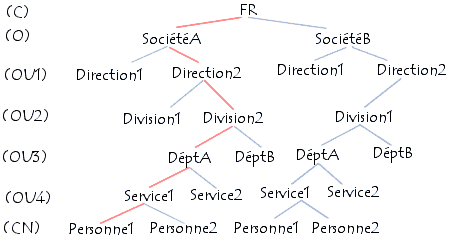
LDAP présente les informations sous forme d'une arborescence d'informations hiérarchique appelée
DIT (Directory Information Tree), dans laquelle les informations, appelées
entrées (ou encore DSE, Directory Service Entry), sont représentées sous forme de branches.
Chaque entrée de l'annuaire LDAP correspond à un objet abstrait ou réel (par exemple une personne, un objet matériel, des paramètres, ...). Chaque entrée est constituée d'un ensemble de paires clés/valeurs appelées attributs.
Chaque entrée est constituée d'un ensemble d'attributs (paires clé/valeur) permettant de caractériser l'objet que l'entrée définit. Il existe deux types d'attributs:
Une entrée est indexée par un nom distinct (DN, distinguished name) permettant d'identifier de manière unique un élément de l'arborescence. Un DN se construit en prenant le nom de l'élément, appelé Relative Distinguished Name
(RDN, c'est-à-dire le chemin de l'entrée par rapport à un de ses parents),
et en lui ajoutant l'ensemble des nom des entrées parentes.
uid=jeapil,cn=pillou,givenname=jean-francoisLe Relative Distinguished Name étant ici "uid=jeapil". Ainsi, on appelle schéma l'ensemble des définitions d'objets et d'attributs qu'un serveur LDAP peut gérer. Cela permet par exemple de définir si un attribut peut possèder une ou plusieurs valeurs. D'autre part, un attribut nommé objectclass permet de définir les attributs étant obligatoires ou facultatifs...
LDAP fournit un ensemble de fonctions (procédures) pour effectuer des requêtes sur les données afin de rechercher, modifier, effacer des entrées dans les répertoires. Voici la liste des principales opérations que LDAP peut effectuer:
LDAP fournit un format d'échange (LDIF, Lightweight Data Interchange Format) permettant d'importer et d'exporter les données d'un annuaire avec un simple fichier texte. La majorité des serveurs LDAP supportent ce format, ce qui permet une grande interopérabilité entre eux. La syntaxe de ce format est la suivante: [<id>] dn: <distinguished name> <attribut> : <valeur> <attribut> : <valeur> ...Dans ce fichier id est facultatif, il s'agit d'un entier positif permettant d'identifier l'entrée dans la base de données.


|