|
|
La concaténation de point est une méthode permettant de stocker les points d'une manière optimale: pour une image monochrome il n'y a, par définition, que deux couleurs, un point de l'image peut donc être codé sur un seul bit pour gagner de l'espace mémoire.
La méthode de compression RLE (Run Length Encoding, parfois notée RLC pour Run Length Coding) est utilisée par de nombreux formats d'images (BMP, PCX, TIFF). Elle est basée sur la répétition d'éléments consécutifs. Le principe de base consiste à coder un premier élément donnant le nombre de répétitions d'une valeur puis le compléter par la valeur à répéter. Ainsi selon ce principe la chaîne "AAAAAHHHHHHHHHHHHHH" compressée donne "5A14H". Le gain de compression est ainsi de (19-5)/19 soit environ 73,7%. En contrepartie pour la chaîne "REELLEMENT", dans lequel la redondance des caractères est faible, le résultat de la compression donne "1R2E2L1E1M1E1N1T"; la compression s'avère ici très coûteuse, avec un gain négatif valant (10-16)/10 soit -60%! En réalité la compression RLE est régie par des règles particulières permettant de compresser lorsque cela est nécessaire et de laisser la chaîne telle quelle lorsque la compression induit un gaspillage. Ces règles sont les suivantes :
Ainsi la compression RLE n'a du sens que pour les données possédant de nombreux éléments consécutifs redondants, notamment les images possédant de large parties uniformes. Cette méthode a toutefois l'avantage d'être peu difficile à mettre en oeuvre. Il existe des variantes dans lesquelles l'image est encodée par pavés de points, selon des lignes, ou bien même en zigzag.
David Huffman a proposé en 1952 une méthode statistique qui permet d'attribuer un mot de code binaire aux différents symboles à compresser (pixels ou caractères par exemple). La longueur de chaque mot de code n'est pas identique pour tous les symboles: les symboles les plus fréquents (qui apparaissent le plus souvent) sont codés avec de petits mots de code, tandis que les symboles les plus rares reçoivent de plus longs codes binaires. On parle de codage à longueur variable (en anglais VLC pour variable code length) préfixé pour désigner ce type de codage car aucun code n'est le préfixe d'un autre. Ainsi la suite finale de mots codés à longueurs variables sera en moyenne plus petite qu'avec un codage de taille constante. Le codeur de Huffman crée un arbre ordonné à partir de tous
les symboles et de leur fréquence d'apparition. Les branches sont construites récursivement
en partant des symboles les moins fréquents.
La construction de l'arbre se fait en ordonnant dans un premier temps les symboles par fréquence d'apparition.
successivement les deux symboles de plus faible fréquence d'apparition sont retirés de la liste
et rattachés à un noeud dont le poids vaut la somme des fréquences des deux symboles. Le symbole
de plus faible poids est affecté à la branche 1, l'autre à la branche 0 et ainsi de suite en considérant
chaque noeud formé comme un nouveau symbole, jusqu'à obtenir un seul noeud parent appelé racine.
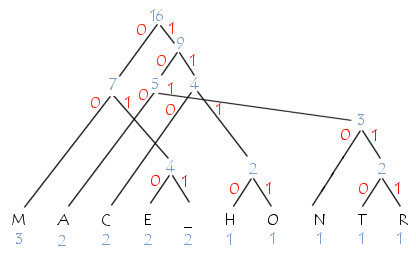
Soit la phrase suivante : "COMMENT_CA_MARCHE". Voici les fréquences d'apparitions des lettres
Voici l'arbre correspondant :
Les codes correspondants à chaque caractère sont tels que les codes des caractères les plus fréquents sont courts et ceux correspondant aux symboles les moins fréquents sont longs :
Les compressions basées sur ce type de codage donnent de bons taux de compressions, en particulier pour les images monochromes (les fax par exemple). Il est notamment utilisé dans les recommandations T4 et T5 de l'ITU-T
Abraham Lempel et Jakob Ziv sont les créateurs du compresseur LZ77, inventé en 1977 (d'où son nom). Ce compresseur était alors utilisé pour l'archivage (les formats ZIP, ARJ et LHA l'utilisent). En 1978 ils créent le compresseur LZ78 spécialisé dans la compression d'images (ou tout type de fichier de type binaire). En 1984, Terry Welch de la société Unisys le modifia pour l'utiliser dans des contrôleurs de disques durs, son initiale vint
donc se rajouter à l'abréviation LZ pour donner LZW.
Le dictionnaire est initialisé avec les 256 valeurs de la table ASCII. Le fichier à compresser est découpé en chaînes d'octets (ainsi pour des images monochromes - codées sur 1 bit - cette compression est peu efficace), chacune de ces chaînes est comparée au dictionnaire et est ajoutée si jamais elle n'y est pas présente.
L'algorithme parcourt le flot d'informations en le codant; si jamais une chaîne est plus petite que le plus grand mot du dictionnaire alors elle est transmise.
Lors de la décompression, l'algorithme reconstruit le dictionnaire dans le sens inverse, ce dernier n'a donc pas besoin d'être stocké.
L'acronyme JPEG (Joint Photographic Expert Group prononcez jipègue ou en anglais djaypègue) provient de la réunion en 1982 d'un groupe d'experts de la photographie, dont le principal souci était de travailler sur les façons de transmettre des informations (images fixes ou animées). En 1986, l'ITU-T mit au point des méthodes de compression destinées à l'envoi de fax. Ces deux groupes se rassemblèrent pour créer un comité conjoint d'experts de la photographie (JPEG). Contrairement à la compression LZW, la compression JPEG est une compression avec
pertes, ce qui lui permet, en dépit d'une perte de qualité, un
des meilleurs taux de compression (20:1 à 25:1 sans perte notable de qualité). Les étapes de la compression JPEG sont les suivantes :
Le format de fichier embarquant un flux codé en JPEG est en réalité appelés JFIF (JPEG File Interchange Format, soit en français Format d'échange de fichiers JPEG), mais par déformation le terme de "fichier JPEG" est couramment utilisé. Il est à noter qu'il existe une forme de codage JPEG sans perte (appelé lossless). Bien que peu utilisé par la communauté informatique en général, il sert surtout pour la transmission d'images médicales pour éviter de confondre des artefacts (purement liés à l'image et à sa numérisation) avec de réels signes pathologiques. La compression est alors beaucoup moins efficace (facteur 2 seulement).
|