|
|
Le morse a été le premier codage a permettre une communication longue distance. C'est Samuel F.B.Morse qui l'a mis au point en 1844. Ce code est composé de points et de tirets (un codage binaire en quelque sorte...). Il permit d'effectuer des communications beaucoup plus rapides que le Pony Express. L'interpréteur était l'homme à l'époque, il fallait donc une bonne connaissance du code... De nombreux codes furent inventés dont le code d'émile Baudot (portant d'ailleurs le nom de code Baudot, les anglais l'appelaient Murray Code). Le 10 mars 1876, le Dr Graham Bell met au point le téléphone, une invention révolutionnaire qui permet de faire circuler de l'information vocale dans des lignes métalliques. Pour l'anecdote, la Chambre des représentants a décidé que l'invention du téléphone revenait à Antonio Meucci. Ce dernier avait en effet déposé une demande de brevet en 1871, mais n'avait pas pu financer celle-ci au-delà de 1874. Ces lignes permirent l'essor des télescripteurs, des machines permettant de coder et décoder des caractères grâce au code Baudot (Les caractères étaient alors codés sur 5 bits, il y avait donc 32 caractères uniquement...). Dans les années 60, le code ASCII (American Standard Code for Information Interchange) est adopté comme standard. Il permet le codage de caractères sur 8 bits, soit 256 caractères possibles.
La mémoire de l'ordinateur conserve toutes les données sous forme numérique. Il n'existe pas de méthode pour stocker directement les caractères. Chaque caractère possède donc son équivalent en code numérique: c'est le code ASCII (American Standard Code for Information Interchange - traduisez " Code Americain Standard pour l'Echange d'Informations"). Le code ASCII de base représentait les caractères sur 7 bits (c'est-à-dire 128 caractères possibles, de 0 à 127).
Le code ASCII a été mis au point pour la langue anglaise, il ne contient donc pas de caractères accentués, ni de
caractères spécifiques à une langue. Pour coder ce type de caractère il faut recourir à un autre code.
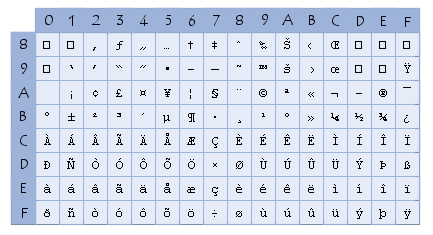
Le code ASCII a donc été étendu à 8 bits (un octet) pour pouvoir coder plus de caractères
(on parle d'ailleurs de code ASCII étendu...).
Le code EBCDIC (Extended Binary-Coded Decimal Interchange Code), développé par IBM, permet de coder des caractères sur 8 bits. Bien que largement répandu sur les machines IBM, il n'a pas eu le succès qu'a connu le code ASCII.
Le code Unicode est un système de codage des caractères sur 16 bits mis au point en 1991. Le système Unicode permet de représenter n'importe quel caractère par un code sur 16 bits, indépendamment de tout système d'exploitation ou langage de programmation. Il regroupe ainsi la quasi-totalité des alphabets existants (arabe, arménien, cyrillique, grec, hébreu, latin, ...) et est compatible avec le code ASCII. L'ensemble des codes Unicode est disponible sur le site http://www.unicode.org.


|