|
|

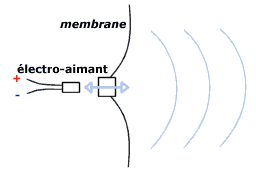
Le son est une vibration de l'air, c'est-à-dire une suite de surpression et de dépressions de l'air par rapport à une moyenne, qui est la pression atmosphérique. D'ailleurs pour s'en convaincre, il suffit de placer un objet bruyant (un réveil par exemple) dans une cloche à vide pour s'apercevoir que l'objet initialement bruyant n'émet plus un seul son dès qu'il n'est plus entouré d'air! La façon la plus simple de reproduire un son actuellement est de faire vibrer un objet. De cette façon un violon émet un son lorsque l'archet fait vibrer ses cordes, un piano émet une note lorsque l'on frappe une touche, car un marteau vient frapper une corde et la faire vibrer. Pour reproduire des sons, on utilise généralement des haut-parleurs. Il s'agit en fait d'une membrane reliée à un électro-aimant, qui, suivant les sollicitations d'un courant électrique va aller en avant et en arrière très rapidement, ce qui provoque une vibration de l'air situé devant lui, c'est-à-dire du son!
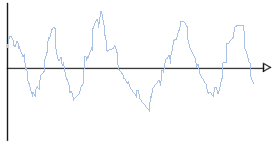
De cette façon on produit des ondes sonores qui peuvent être représentées sur un graphique comme les variations de la pression de l'air (ou bien de l'électricité dans l'électro-aimant) en fonction du temps. On obtient alors une représentation de la forme suivante:
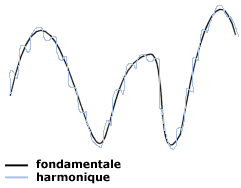
Cette représentation d'un son est appelée spectre de modulation d'amplitude (modulation de l'amplitude d'un son en fonction du temps). Le sonogramme représente par contre la variation des fréquences sonores en fontion du temps. On peut remarquer qu'un sonogramme présente une fréquence fondamentale, à laquelle se superposent des fréquences plus élevées, appelées harmoniques.
C'est ce qui permet d'arriver à distinguer plusieurs sources sonores: les sons graves auront des fréquences basses, et les sons aigus des fréquences élevées
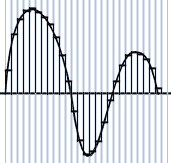
Pour pouvoir représenter un son sur un ordinateur, il faut arriver à le convertir en valeurs numériques, car celui-ci ne sait travailler que sur ce type de valeurs. Il s'agit donc de relever des petits échantillons de son (ce qui revient à relever des différences de pression) à des intervalles de temps précis. On appelle cette action l'échantillonnage ou la numérisation du son. L'intervalle de temps entre deux échantillon est appelé taux d'échantillonnage. Etant donné que pour arriver à restituer un son qui semble continu à l'oreille il faut des échantillons tous les quelques 100000ème de seconde, il est plus pratique de raisonner sur le nombre d'échantillon par seconde, exprimés en Hertz (Hz). Voici quelques exemples de taux d'échantillonnage et de qualités de son associées:
La valeur du taux d'échantillonnage, pour un CD audio par exemple, n'est pas arbitraire, elle découle en réalité du théorème de Shannon. La fréquence d'échantillonnage doit être suffisamment grande, afin de préserver la forme du signal. Le Théorème de Nyquist - Shannon stipule que la fréquence d'échantillonnage doit être égale ou supérieure au double de la fréquence maximale contenue dans ce signal. Notre oreille perçoit les sons environ jusqu'à 20000 Hz, il faut donc une fréquence d'échantillonnage au moins de l'ordre de 40 000 Hz pour obtenir une qualité satisfaisante. Il existe un certain nombre de fréquences d'échantillonnage normalisées :
A chaque échantillon (correspondant à un intervalle de temps) est associé une valeur qui détermine la valeur de la pression de l'air à ce moment, le son n'est donc plus représenté comme une courbe continue présentant des variations mais comme une suite de valeurs pour chaque intervalle de temps:
L'ordinateur travaille avec des bits, il faut donc déterminer le nombre de valeurs que l'échantillons peut prendre, cela revient à fixer le nombre de bits sur lequel on code les valeurs des échantillons.
Enfin, la stéréophonie nécessite deux canaux sur lesquels on enregistre individuellement un son qui sera fourni au haut-parleur de gauche, ainsi qu'un son qui ser diffusé sur celui de droite. Un son est donc représenté (informatiquement) par plusieurs paramètres:
Il est simple de calculer la taille d'une séquence sonore non compressée. En effet, en connaissant le nombre de bits sur lequel est codé un échantillon, on connait la taille de celui-ci (la taille d'un échantillon est le nombre de bits...). Pour connaître la taille d'une voie, il suffit de connaître le taux d'échantillonnage, qui va nous
permettre de savoir le nombre d'échantillons par seconde, donc la taille qu'occupe une seconde de musique. Celle-ci
vaut:
Ainsi, pour savoir l'espace mémoire que consomme un extrait sonore de plusieurs
secondes, il suffit de multiplier la valeur précédente par le nombre de seconde:
Enfin, la taille finale de l'extrait est à multiplier par le nombre de voies (elle sera alors
deux fois plus importante en stéréo qu'en mono...).
Taux d'échantillonnage x Nombre de bits x nombre de secondes x nombre de voies
|