
|
|
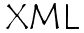
XML permet de définir la structure du document uniquement, ce qui permet d'une part de pouvoir définir séparément la présentation de ce document, d'autre part d'être capable de récupérer les données présentes dans le document pour les utiliser. Toutefois la récupération des données encapsulées dans le document nécessite un outil appelé analyseur syntaxique (en anglais parser), permettant de parcourir le document et d'en extraire les informations qu'il contient.
L'analyseur syntaxique (généralement francisé en parseur) est un outil
logiciel permettant de parcourir un document et d'en extraire des informations.
On distingue deux types de parseurs XML :
Les analyseurs XML sont également divisés selon l'approche qu'ils utilisent pour traiter le document. On distingue actuellement deux types d'approches :
DOM (Document Object Model, traduisez modèle objet de document) est une spécification du W3C (World Wide Web Consortium) définissant la structure d'un document sous forme d'une hiérarchie d'objets, afin de simplifier l'accès aux éléments constitutifs du document. Plus exactement DOM est un langage normalisé d'interface (API, Application Programming Interface), indépendant de toute plateforme et de tout langage, permettant à une application de parcourir la structure du document et d'agir dynamiquement sur celui-ci. Ainsi Javascript et ECMAScript utilisent DOM pour naviguer au sein du document HTML, ce qui leur permet par exemple de pouvoir récupérer le contenu d'un formulaire, le modifier, ... DOM se divise en deux spécifications :
SAX est une API basée sur un modèle événementiel, cela signifie
que SAX permet de déclencher des événements au cours de l'analyse
du document XML.
Soit le document XML suivant : <personne> <nom>Pillou</nom> <prenom>Jean-François</prenom> </personne>Une interface événementielle telle que l'API SAX permet de créer des événements à partir de la lecture du document ci-dessus. Les événements générés seront : start document start element: personne start element: nom characters: Pillou end element: nom start element: prenom characters: Jean-François end element: prenom end element: personne end documentAinsi une application basée sur SAX peut gérer uniquement les éléments dont elle a besoin sans avoir à construire en mémoire une structure contenant l'intégralité du document. L'API SAX définit les quatre interfaces suivantes :
Les analyseurs utilisant l'interface DOM souffrent du fait que cette API impose de construire un arbre en mémoire contenant l'intégralité des éléments du document en mémoire quelle que soit l'application. Ainsi pour de gros documents (dont la taille est proche de la quantité de mémoire présente sur la machine) DOM devient insuffisant. De plus, cela rend l'utilisation de DOM lente, c'est la raison pour laquelle la norme DOM est généralement peu respectée car chaque éditeur l'implémente selon ses besoins, ce qui provoque l'apparition de nombreux parseurs utilisant des interfaces propriétaires... Ainsi de plus en plus d'applications se tournent vers des API événementielles telles que SAX, permettant de traiter uniquement ce qui est nécessaire.

|

